이 글은 DZone 에 기고된 The Developer's Guide to Collections: Sets 글을 제 마음대로 번역한 글입니다. (+구글번역)
마음에 안 들거나 제가 잘못 이해한 부분은 알려주시면 수정하도록 하겠습니다.
The Developer's Guide to Collections: Sets - DZone Java
See how sets work in Java and how to make the best use of them by exploring their associated operations and recommended practices.
dzone.com
Set은 Java Collections Framework (JCF) 에서 가장 수학적인 추상화 중 하나이며, 위상 또는 상태 플래그, 고유한 Collection 및 고유 요소들의 순서가 지정된 그룹을 비롯한 다양한 Use case에서 필수적인 역할을 합니다. 이러한 다양한 목표를 지원하기 위해 Set 인터페이스 및 구현 클래스에는 Georg Cantor가 개발한 Set Theory의 개념과 특성을 밀접하게 반영하는 의미 체계가 포함되어 있습니다.
The Developer's Guide to Collections 시리즈에 이어서 인터페이스가 모방하는 수학적인 기초에 특히 주의하면서, Set 인터페이스 및 관련 구현체를 살펴 봅니다. 또한 Set 인터페이스를 실행 가능하고 사용 가능한 구현 클래스로 전환하는 계층 구조를 살펴 봅니다. 마지막으로 각 구현 클래스의 장단점과 각각이 가장 적합한 조건을 비교합니다. 이 심층 조사를 시작하기 위해, JCF : Set Theory에서 Set의 가장 간단하면서도 기본적인 측면부터 시작해야합니다.
The Concept of a Set
수학적인 내용에서의 Set은 집합으로 표현할 예정입니다.
집합의 개념은 1800년대 후반 독일의 수학자 Georg Cantor에 의해 처음으로 공식화되었으며 집합론이라고도 합니다. 수학에서의 집합은 A = {1, 2, 4} 와 같이 중괄호로 표시되는 고유한 요소의 모음입니다. 어떤 값 a가 집합 A에 포함 된 경우 a는 집합 A의 요소 또는 구성원으로 간주되며, 기호 a ∈ A로 표시됩니다. 어떤 경우에는 약식으로 집합의 구성원을 in 관계로 표현합니다. (즉, a는 A에 속함, 원문 : a is in A). 요소를 포함하지 않는 집합은 빈집합 또는 공집합이라고하며 {} 또는 기호 ∅ (즉, 공집합 A는 A = {} 또는 A = ∅ 임)로 표시됩니다. 보다 공식적으로 공집합은 카디널리티가 0인 집합 A입니다. | A | = 0.
A의 모든 요소가 B에 포함된 경우 집합 A는 다른 집합 B의 부분집합으로 간주하고, A ⊆ B로 표시됩니다.
예를 들어 A = {1, 2} 는 B = {1, 2, 3, 4} 의 부분집합입니다.
하나의 부분집합 A가 B에 포함된 모든 요소를 가지고 있지만, B와 같지 않은 경우에는 진부분집합으로 간주하고 A ⊂ B로 표시합니다. (즉, A ⊆ B 및 A ≠ B)
예를 들어, A = {1, 2}은 B = {1, 2, 3, 4}의 진부분집합입니다. (A ⊂ B)
C = {1, 2, 3, 4}는 B의 부분집합이지만, (C = B이므로 C ⊆ B) C는 B의 진부분집합은 아닙니다. (즉, C ⊄ B)
또한 집합에는 집합에서 요소를 추가하거나 제거하는 일련의 이항연산들이 있습니다.
이러한 연산 중 첫 번째는 A ∪ B로 표시되는 두 집합 A와 B의 합집합으로, 결과적으로 A와 B의 요소가 결합됩니다. 예를 들어 A = {1, 3, 4} 이고 B = {1, 2, 5, 7} 인 경우, A ∪ B = {1, 2, 3, 4, 5, 7} 가 됩니다. 집합의 요소가 고유하므로 1은 한 번만 포함됩니다.
A ∩ B로 표시되는 두 집합 A와 B의 교집합은 A와 B 사이에 공통되는 요소만을 가집니다. 예를 들어 A = {1, 2, 3, 4}이고 B = {2, 4, 5}, A ∩ B = {2, 4} 가 됩니다.
마지막으로, A \ B로 표시되는 두 집합 A와 B의 차집합은 B의 구성원이 아닌 A의 모든 구성원의 집합입니다. (때로는 공식적으로 비대칭 차집합이라고도 함)
asymmetric difference의 번역이 애매하네요. symmetric difference는 공식명칭으로 대칭차집합이라고 되어있는데...
예를 들어, A = { 1, 2, 3, 4} 및 B = {2, 4, 5}, A \ B = {1, 3}. 이러한 기본 이항연산은 아래 그림 같이 벤 다이어그램을 사용하여 시각적으로 가장 잘 설명됩니다.
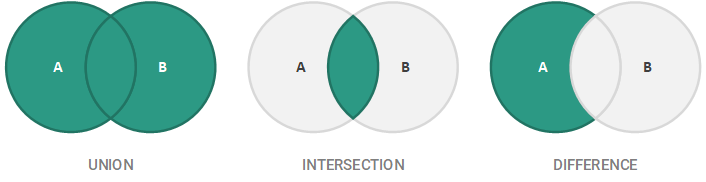
집합의 특징과 연산을 다음과 같이 요약할 수 있습니다.
- 집합 : 고유값 모음
- 요소 : 집합에 포함된 값
- 널 또는 공집합 : 0 요소 집합 (카디널리티가 0 인 집합)
- 부분집합 : 요소가 다른 집합에 포함된 집합
- 진부분집합 : 다른 집합의 부분집합이지만, 같지 않은 집합
- 합집합 : 두 집합의 고유의 요소를 합친 결과
- 교집합 : 두 집합 사이에 공통적인 요소
- 차집합 : 한 집합에는 포함되지만, 다른 집합에는 포함되지 않은 요소
다음 섹션에서는 이러한 수학적 원리를 Set 인터페이스로 변환하고, 집합의 공식 정의와 Java Set 인터페이스 사이에 공통적 인 기능을 살펴봅니다.
The Set Interface
JDK 9 (Java Development Kit) 의 Set 인터페이스에서 눈에 띄는 부분은 Collection 인터페이스에서 찾을 수 없는 새로운 메소드를 도입하지 않았다는 것 입니다. Set과 Collection의 유일한 차이점은 mutation methods의 의미 체계에서 찾을 수 있습니다. JDK 9 에서의 Set 인터페이스는 아래 Snippet에 나열되어 있습니다.
public interface Set<E> extends Collection<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean retainAll(Collection<?> c);
boolean removeAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
default Spliterator<E> spliterator() { /* ... */ }
}Set 인터페이스에서 default 구현이 재정의되는 유일한 메소드는 spliterator() 입니다.
이전에 List 인터페이스에서 살펴본 것 처럼, 범용 Collection이 아닌 Set 작업에 대해 반환된 Spliterator를 최적화하기 위해 spliterator 메소드의 재정의가 수행됩니다. 다음 섹션에서 이 default 구현에 대해 자세히 살펴 보겠습니다.
Set 및 Collection 인터페이스의 주요 차이점은 add, addAll, removeAll, 그리고 retainAll과 같은 mutation method들의 의미 체계에서 찾을 수 있습니다. 표준 Collection에서 이러한 메소드들은 단순히 Collection의 요소를 각각 추가 및 제거, 그리고 유지합니다. Set에서 이러한 연산은 수학의 집합론에 설명된 이진 집합의 특징 및 연산에 해당합니다. 예를 들어, 집합에 이미 존재하는 요소를 추가하더라도 고유한 값만 포함할 수 있으므로 집합이 변경되지 않습니다 (add가 수행되지 않음).
또한 addAll은 입력된 Collection과 Set의 합집합을 수행합니다 (고유값 유지). removeAll은 입력된 Collection과 Set의 차집합을 수행합니다. 그리고 retainAll은 입력된 Collection과 Set의 차집합을 수행합니다. 마찬가지로, Set 클래스의 생성자는 Set에 중복값이 없는 경우에만 입력된 Collection의 요소가 추가될 수 있도록 합니다.
add(E e)
이 선택작업은 - 구현에 필요하지 않으며 구현이 지원하지 않는 경우 UnsupportedOperationException을 throw 할 수 있습니다. - 입력된 요소가 Set에 아직 포함되지 않은 경우 (중복이 아닌 경우) Set에 요소를 추가하고, Set이 변경된 경우 true를 반환합니다. (즉, 추가가 성공한 경우) 요소 a가 임의의 요소인 b와 중복이라면, a.equals(b) 는 true를 반환합니다. Set에 입력된 요소의 중복이 있다면 add는 수행되지 않고 false를 반환합니다.
addAll(Collection c)
이 선택작업은 입력된 Collection의 중복값을 제외한 모든 요소를 Set에 추가하고, Set이 변경된 경우 true를 반환합니다. 입력된 Collection이 Set인 경우 이 메소드는 효과적으로 두 Set의 합집합(union)을 수행합니다. 아래 그림에서 합집합을 확인할 수 있습니다.

removeAll(Collection c)
이 선택작업은 입력된 Collection에 있는 모든 요소를 Set에서 제거하고, Set이 변경된 경우 true를 반환합니다. 입력된 Collection이 Set인 경우 이 메소드는 효과적으로 두 Set의 차집합(difference)을 수행합니다. 아래 그림에서 차집합을 확인할 수 있습니다.

retainAll(Collection c)
이 선택작업은 제공된 Set에 있는 요소와 입력된 Collection의 요소의 공통 요소만 유지하며, Set이 변경되면 true를 반환합니다. 입력된 Collection이 Set인 경우 이 메소드는 효과적으로 두 Set의 교집합(intersection)을 수행합니다. 아래 그림에서 교집합을 확인할 수 있습니다.

Spliterator
다른 많은 Collection 유형과 마찬가지로 Set 인터페이스는 Set 유형의 특징에 더 적합한 Spliterator를 반환하기 위해 spliterator 메서드를 재정의합니다. Set의 경우 Spliterator에는 JDK 9 기본 구현에 설명된대로 Set#spliterator 메소드에 대해 각 요소가 구별되는 필수 특성이 있습니다.
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT);
}Spliterator는 복잡한 주제이고, 이 시리즈의 범위를 벗어납니다. 자세한 내용은 공식 Spliterator 문서를 참조하세요.
equals & hashCode
Set의 equals 메소드는 두 Set의 요소별 동등성(equality)을 기반으로 합니다. 따라서 대상 객체가 Set과 같으려면 Set 객체이거나 Set을 확장한 객체여야 하며, Set과 동일한 수의 요소가 있어야 하고 각 요소는 Set의 요소와 일치해야 합니다. 마찬가지로, Set의 hashCode 메소드는 해당하는 요소들의 hashCode 합계이고, 결과적으로 두 Set이 동등(equals)하다는 것은 두 Set A와 B의 hashCode가 동등(equals)하다는 것이 됩니다. (즉, A.equals(B)).
summary
일반적으로 Set에 요소를 추가하는 모든 메소드들은 중복 항목이 추가되지 않고 언제라도 Set의 모든 요소가 고유하다는 것을 보장합니다. 이것은 클래스 불변(invariant)에 해당하며 Set의 Lifecycle을 절대 어기지 않습니다. Set 객체가 입력되면 Collection에서 작동하는 메서드는 다음과 같이 집합의 이항연산을 수행합니다.
- 합집합 (Union) : addAll
- 교집합 (Intersection) : retainAll
- 차집합 (Asymmetric difference) : removeAll
일반적으로 Set 클래스에 대한 스펙은 표준 Collection 인터페이스를 구현하면서 수학 집합에 대한 특징과 연산을 거의 모방합니다.
The Set Hierarchy
Set의 수학적 개념에 대한 기초적인 이해와 Set 인터페이스가 이러한 개념을 통합하는 방법에 대한 이해를 바탕으로 이제 Set 인터페이스에 대한 클래스 계층 구조를 탐색 할 수 있습니다. JDK 9 Set 계층은 아래 그림에 설명되어 있습니다. 녹색 상자는 인터페이스를 나타내고, 파란색 상자는 추상 클래스를 나타내고, 보라색 상자는 구체적인 구현 클래스를 나타냅니다.
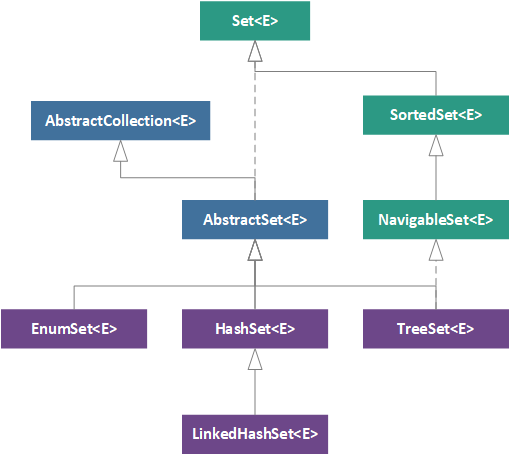
The Developer's Guide to Collections에서 다루었듯이, Set 계층 구조의 최상위는 Set 인터페이스이고 그 뒤에 AbstractSet 추상 클래스가 이어집니다. (이는 AbstractCollection 추상 클래스를 확장함) 이 추상 클래스에서 (1) EnumSet, (2), HashSet, (3) LinkedHashSet의 세 가지 구체적인 구현체가 파생됩니다. Set 인터페이스의 이러한 직계 조상 외에도 계층 구조에는 (1) SortedSet 및 (2) NavigableSet의 두 가지 다른 인터페이스가 포함됩니다. 마지막 구체적인 구현체인 TreeSet은 SortedSet 인터페이스를 확장한 NavigableSet 인터페이스를 구현합니다.
SortedSet
SortedSet 인터페이스는 요소의 전순서(total ordering)를 규정하며, 각 요소는 Set의 다른 요소에 대해 상대적으로 정렬됩니다. 이 순서는 명시적인 Comparator 객체를 사용하거나 자연스러운 순서(natural ordering)를 통해 수행됩니다. (각 요소가 Comparable 인터페이스를 구현하는 경우) 이 순서를 지원하기 위해 SortedSet을 구현하는 클래스에 의해 반환된 Iterator는 명시된 순서 (즉, 명시적인 Comparator 순서 또는 자연스러운 순서(natural ordering))에 따라 오름차순으로 Set을 탐색합니다. 이 인터페이스는 또한 SortedSet에 있는 요소의 정렬된 액세스를 허용하는 다음 메서드를 제공합니다.
- first : Set에서 첫 번째 (가장 낮은) 요소를 반환합니다.
- last : Set에서 마지막 (가장 높은) 요소를 반환합니다.
- subSet(E fromElement, E toElement) : fromElement(포함)에서 toElement(제외)까지의 요소를 포함하는 새로운 세트를 반환합니다.
- headSet(E toElement) : Set의 헤드에서 toElement까지의 요소를 포함하는 새로운 Set을 반환합니다.
- tailSet(E fromElement) : fromElement에서 끝까지의 요소를 포함하는 새로운 Set을 반환합니다.
NavigableSet
NavigableSet은 클라이언트가 일부 검색 기준에 가장 가까운 대상을 얻을 수 있도록 하는 메소드를 제공하여 이 정의를 확장합니다. 이 인터페이스는 Set에 대한 검색 기반 액세스를 지원하기 위해 다음과 같은 방법을 제공합니다.
- lower(E element) : 제공된 요소보다 작은 가장 큰 요소를 반환합니다.
- high (E element) : 제공된 요소보다 큰 최소 요소를 반환합니다.
- floor (E element) : 제공된 요소보다 작거나 같은 가장 큰 요소를 반환합니다.
- ceiling (E element) : 제공된 요소보다 크거나 같은 최소 요소를 반환합니다.
이러한 모든 메서드에 대해 원하는 기준과 일치하는 요소를 찾을 수 없으면 null이 반환됩니다. Java에서 Set을 구성하는 계층 구조를 이해 했으므로, 이제 구체적인 구현 클래스와 상대적인 장/단점을 더 자세히 살펴볼 수 있습니다.
EnumSet
EnumSet 클래스는 열거형 (Enum) 을 지원하도록 설계된 특수 목적의 Set입니다. 많은 애플리케이션에서 일부 상태와 관련된 플래그 값을 간결하게 표현하기 위한 수단이 필요합니다. 예를 들어, Typhography 또는 워드프로세서 응용 프로그램을 만드는 경우에, 특정 텍스트 집합이 굵게, 밑줄 또는 기울임 꼴인지 여부를 나타내는 플래그가 필요할 수 있습니다. 많은 기본 응용 프로그램 (예 : C 또는 C ++로 작성된 응용 프로그램)에서 비트 필드가 사용됩니다. 여기서 원하는 각 플래그에 연속적인 비트 값 (예 : 0x01, 0x02, 0x04 등)이 지정되고 비트 연산이 플래그를 설정하는데 사용됩니다. 마스크는 특정 플래그가 설정되었는지 확인하는 데 사용됩니다.
이러한 유형의 플래그는 매우 효율적이지만, 번거롭고 오류가 발생하기 쉽습니다. Java는 대안으로 enum 클래스에서 일부 열거형 상수값을 (모두 포함하거나 모두 포함하지 않을 수 있음) 기반으로 생성하고, 비트 벡터로 나타내는 EnumSet을 제공합니다. 이 내부 표현은 매우 효율적이고 매우 간결하여 대부분의 플래그 기반 사용 사례에 적합할 만큼 충분히 높은 성능 이점을 제공합니다. EnumSet의 가능한 사용 예가 아래 목록에 나와 있습니다.
public interface Style {
public String apply(String text);
}
public enum BasicStyle implements Style {
BOLD {
public String apply(String text) { return "<strong>" + text + "</strong>"; }
},
UNDERLINE {
public String apply(String text) { return "<u>" + text + "</u>"; }
},
ITALIC {
public String apply(String text) { return "<em>" + text + "</em>"; }
};
}
public class HtmlFormatter {
public String format(String text, Set<? extends Style> styles) {
String formattedText = text;
for (Style style: styles) {
formattedText = style.apply(formattedText);
}
return formattedText;
}
}
HtmlFormatter formatter = new HtmlFormatter();
String text = formatter.format("Hello, world!", EnumSet.of(BasicStyle.BOLD, BasicStyle.ITALIC));
System.out.println(text); // Output: <em><strong>Hello, world!</strong></em>비교를 위해 비트 필드와 비트 비교 연산을 사용하여 유사한 방식으로 동일한 논리를 구현할 수 있습니다.
public interface Styles {
public static final int BOLD = 0x01;
public static final int UNDERLINE = 0x02;
public static final int ITALIC = 0x04;
}
public class HtmlFormatter {
public String format(String text, int styles) {
String formattedText = text;
if ((styles & Styles.BOLD) == Styles.BOLD) {
formattedText = "<strong>" + formattedText + "</strong>";
}
if ((styles & Styles.UNDERLINE) == Styles.UNDERLINE) {
formattedText = "<u>" + formattedText + "</u>";
}
if ((styles & Styles.ITALIC) == Styles.ITALIC) {
formattedText = "<em>" + formattedText + "</em>";
}
return formattedText;
}
}
HtmlFormatter formatter = new HtmlFormatter();
String text = formatter.format("Hello, world!", Styles.BOLD | Styles.UNDERLINE);
System.out.println(text);비트 필드 대안이 더 간결해 보일 수 있지만 해당 언어(Java)에서는 훨씬 덜 정확합니다. 예를 들어, 열거된 Style (또는 Style 인터페이스를 구현하는 객체) 뿐만 아니라 모든 정수 값을 Style로 제공할 수 있습니다. 또한 Enum 및 EnumSet을 사용하면 각각 여러 Style에 대한 형식 논리 및 반복을 캡슐화 할 수 있습니다. 비트 필드의 경우 가능한 각 스타일 값이 제공되었는지 확인하고 그에 따라 제공된 문자열의 형식을 지정해야합니다.
HashSet
HashSet은 단순히 HashMap에 의해 지원되는 Set이며, Set 요소들의 순서는 보장하지 않으면서 null 값을 허용합니다. 일반적으로 add, remove, contains 및 size 메서드는 상수 시간에 실행됩니다. (요소를 나타내는 객체에 대해 적절하게 구성된 hashCode 메소드라고 가정) 반복의 경우 HashSet 클래스는 요소 수와 버킷 수 (또는 용량) 의 합계에 대해 비례합니다. HashMap 객체를 튜닝하기 위해 두 가지 옵션이 제공됩니다.
- 초기 용량 : 생성 시 Set의 용량
- 부하율 : 용량이 자동으로 증가하기 전 HashSet 용량 대비 요소의 비율 (자세한 내용은 HashMap 문서 참조)
일반적으로 요소의 순서가 필요하지 않은 경우에, HashSet 클래스는 전반적으로 최상의 성능을 제공하고 정렬되지 않은 Set에 사용되는 기본 Set 구현으로 간주되어져야 합니다.
TreeSet
TreeSet은 명시적인 Comparator 객체 또는 자연스러운 순서(natural ordering)를 통해 요소의 전순서(total ordering)를 제공합니다. 내부적으로 이 구현체는 생성 시 요소를 정렬하고, Iterator 구현을 사용하여 순서대로 반복할 수 있는 TreeMap에 의해 지원됩니다. 일반적으로 이 클래스는 add, remove, 그리고 contains 메소드에 대한 O(logN) 성능을 제공하며, 요소의 순서가 필요할 때 사용해야 합니다. 대부분의 다른 경우에는 HashSet을 사용해야 합니다. 또한 이 Set 구현체는 자연스러운 순서(natual ordering)가 사용되거나 명시적으로 제공된 Comparator 객체가 null을 지원하지 않는 경우, null 값을 거부한다는 점에 유의해야합니다.
LinkedHashSet
LinkedHashSet은 정렬되지 않은 HashSet과 완전히 정렬된 TreeSet 사이의 절충안입니다. 이 Set 구현체는 LinkedList에 의해 지원되며 삽입된 순서대로 해당 요소가 반복되도록 보장합니다. 가장 최근에 추가된 요소가 Set의 마지막 위치를 차지합니다. 예를 들어, 일부 요소 A가 Set에 추가된 다음에 일부 요소 B가 추가된 경우, 이 Set를 반복하면 A 다음에 B가 표시됩니다.
삽입된 순서를 보장하는 이러한 특징은 요소를 확정적으로 반복해야 하는 Set 구현체를 요구하는 클라이언트에게 중요합니다. 일반적으로 add, remove, 그리고 contains의 실행 성능은 HashSet의 것과 성능이 거의 같습니다. 또한 이 Set 구현체는 모든 선택작업을 지원하고 null 값을 추가할 수 있습니다. (최대 하나의 null 값)
Comparison
다음 표에서는 특정 시나리오에 가장 적합한 Set 구현체를 결정하고, 이러한 서로 다른 구현체 간의 성능 균형을 이해하는 데 도움이 되는 몇 가지 일반적인 지침을 제공합니다.
각 Set 구현체의 장/단점에 대한 자세한 내용은 이 Set Implementation Oracle 문서를 참조하십시오.
| SET | DESCRIPTION |
| EnumSet | 주로 비트 필드의 대안으로 사용됩니다. 이 Set은 플래그들의 집합에 대한 반복과 같이 일련의 열거형 상수를 Collection 내에서 함께 그룹화해야 할 때마다 사용해야합니다. |
| HashSet | HashMap이 지원하는 일반적으로 성능이 좋은 Set 구현체입니다. 이 구현체는 생성 시 초기 용량 및 부하율을 튜닝할 수 있게 해주고, Set의 요소 순서가 필요하지 않을 때 사용되는 기본 구현체입니다. |
| TreeSet | 요소가 명시적인 Comparator 객체 또는 자연스러운 순서에 (사용된 생성자에 따라 다름) 따라 정렬되도록 보장하고 add, remove, 그리고 contains 메소드를 실행할 때 O(logN) 의 효율성을 나타내는 정렬된 Set입니다. 이 구현체는 요소에 대해 전순서(total ordering)가 필요한 경우에만 사용해야 하며, 전순서(total ordering)가 필요하지 않다면 HashSet을 사용해야합니다. |
| LinkedHashSet | HashSet의 효율성과 TreeSet의 전순서(total ordering) 간의 절충안 : 이 구현체는 HashSet의 성능과 거의 동일한 성능으로 삽입된 순서를 보장합니다. 이 구현체는 전순서(total ordering)가 아니라, 확정적으로 일관된 순서(deterministic consistent ordering)가 필요할 때 사용해야합니다. 일관된 순서(consistent ordering)가 필요하지 않은 경우 HashSet을 대신 사용해야합니다. |
Conclusion
Set은 JCF의 더 수학적 측면 중 하나이고, 플래그 값 (이전에는 비트 필드로 표시됨) 및 고유 요소의 모음을 포함하여 매우 중요한 UseCases이 많이 있습니다. Set의 수학적 특성이 표준 Collection 인터페이스 메소드와 교차하는 것처럼 보일 수 있지만, JCF는 이러한 형식 개념을 기존 메소드와 간결하게 통합하여 Collection 인터페이스에서 상속된 메소드에 부가적인 메소드를 추가하지 않는 Set 인터페이스를 생성합니다. 또한 구현체들은 enum 상수의 캡슐화, 상수시간 성능, 그리고 요소들의 순서를 포함한 유용한 기능의 배열을 제공합니다. Set은 가장 널리 사용되는 Collection 유형은 아니지만, 많은 정확한 UseCases에서 중요한 역할을 하므로 자바 개발자의 도구에 있어야 합니다.